基于本體的金融知識圖譜自動化構建 CCKS2020評測第五名方法總結與推廣
在2020年CCKS(全國知識圖譜與語義計算大會)舉辦的“基于本體的金融知識圖譜自動化構建技術評測”中,我們團隊提出的方案最終取得了第五名的成績。該評測任務聚焦于金融領域,要求參賽者利用給定的非結構化文本和預定義的金融本體,自動化地抽取實體、關系及屬性,以構建結構化的知識圖譜。本文旨在我們的核心方法,并探討其在更廣泛場景下的推廣潛力。
方法融合與迭代的自動化構建流程
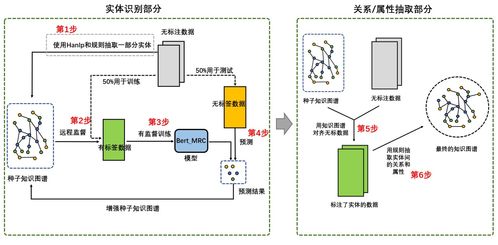
我們的方法并非依賴單一的模型或技巧,而是構建了一個多階段、多模型協同的流水線系統,核心思想是“融合先驗、迭代優化”。主要步驟如下:
1. 本體引導的實體識別與分類:
金融本體提供了嚴謹的概念層次和約束,這是寶貴的先驗知識。我們采用基于BERT的序列標注模型進行命名實體識別(NER),但關鍵創新在于將本體中的類別信息(如“公司”、“金融產品”、“人物”)融入到模型的訓練中。我們構建了一個本體感知的標簽體系,并在輸入層通過特殊標記或特征嵌入的方式,讓模型“感知”到當前文本片段可能涉及的金融概念,從而提升了對專業術語和歧義實體的識別準確率。
2. 關系與屬性的聯合抽取:
針對金融文本中實體關系緊密交織的特點,我們沒有將關系抽取和屬性抽取完全割裂。我們設計了一個基于指針網絡的聯合抽取模型。該模型以識別出的實體對和上下文為輸入,同時預測關系類型和屬性值。這種方法能有效捕捉關系與屬性之間的內在聯系,例如,“A公司控股B公司(關系)”與“持股比例(屬性)”常常同時出現,聯合建模減少了誤差傳播。
3. 基于規則與一致性校驗的后處理:
純端到端的深度學習模型在處理復雜金融邏輯時仍有不足。我們引入了一個后處理模塊,利用本體中定義的概念不相交性、屬性值域等約束,以及人工的少量高質量規則,對自動抽取的結果進行校驗和修正。例如,檢查“成立日期”屬性的格式是否符合時間規范,或根據“是...的子公司”關系推斷并補全反向的“擁有子公司”關系,確保圖譜的邏輯一致性。
4. 迭代式知識融合與自增強:
這是我們的核心優化策略。初始構建的圖譜難免存在噪聲和缺失。我們設計了一個輕量級的迭代流程:將首輪抽取結果中置信度較高的部分(如高概率實體和關系)作為“準知識”,反哺給后續的抽取模型。在第二輪處理時,模型能夠參考這些已存在的知識來理解上下文,從而提升對模糊提及或長距離依賴關系的抽取能力。這種“抽取-融合-再抽取”的閉環,有效實現了系統的自我增強。
技術推廣:超越金融領域的通用化啟示
雖然本次評測聚焦金融,但我們的方法框架具有向其他垂直領域推廣的普適價值。
- 領域適配性強:其核心在于“領域本體+深度學習+邏輯規則”的融合范式。對于醫療、法律、工業等任何擁有或可以構建領域本體的場景,只需將預訓練模型(如BERT)替換為領域預訓練模型(如BioBERT、Legal-BERT),并導入對應的領域本體,整個流水線的主體架構可快速復用。本體作為領域知識的“骨架”,確保了構建過程的方向性和專業性。
- 解決數據稀缺問題:在多數專業領域,高質量的標注數據稀缺。我們的方法通過充分利用本體(一種結構化知識)來引導和監督數據驅動的模型,降低了對海量標注數據的依賴。迭代自增強機制也能在一定程度上利用模型自身產出的高置信結果來擴充訓練數據,緩解冷啟動問題。
- 提升圖譜質量與可用性:后處理中的一致性校驗環節至關重要,它直接關系到產出圖譜的邏輯質量,是知識圖譜能否應用于風控、問答、推理等下游任務的關鍵。這一環節的設計思想可以推廣到任何對數據質量要求嚴苛的應用中。
- 擁抱大模型時代的新機遇:在當前大語言模型(LLM)興起的背景下,我們的框架可以進一步升級。例如,可以利用LLM強大的零樣本/少樣本理解能力,替代或輔助傳統的NER和關系抽取模型,尤其是在處理復雜、隱含的關系時。本體則可以作為約束和引導LLM生成的結構化“思維框架”,確保其輸出符合領域規范,避免“幻覺”,實現“大模型感知能力”與“本體領域知識”的強強聯合。
###
在CCKS2020評測中取得第五名,是對我們提出的“本體引導、聯合抽取、規則校驗、迭代增強”技術路線的有效驗證。該方法平衡了數據驅動與知識驅動的優勢,在保證自動化程度的顯著提升了金融知識圖譜構建的準確性與一致性。其模塊化的設計理念和融合核心思想,為在更多數據有限但知識豐富的垂直領域,進行高效、可靠的知識圖譜自動化構建,提供了可借鑒、可推廣的解決方案。結合大模型等新技術,這一框架有望釋放出更大的潛力。
如若轉載,請注明出處:http://www.vdjbole.cn/product/17.html
更新時間:2026-01-07 07:43:48